
Unstructured document processing strategies
In our opinion, there are 3 different approaches worth considering when looking for a solution to help us process unstructured documents:
- Cloud based document processing services
- Proprietary LLM’s
- Open source LLM’s
Cloud based document processing services
Cloud providers are offering specialized tools for extracting data from documents, for example:
- AWS (Textract)
- Azure (AI Document Intelligence)
- Google (Document AI)
These solutions are similar and have many features like OCR, table extraction, filters, etc built in, and they support many document formats out of the box. We can not run these services locally. To use these services, we must integrate using API’s, so the source documents must be submitted to the cloud.
Pros:
- Getting started is easier
- Accuracy
- Scalability
- No local server infrastructure is needed
Cons:
- Vendor lock-in
- Limited flexibility
- Data privacy concerns
Proprietary LLM’s
The well known AI providers are offering APIs to their Large Language Model. When using this approach, we must submit the prepared document to the model through its API, and the processing is taking place in the provider's infrastructure.
Examples for proprietary LLM’s:
- OpenAI GPT
- Anthropic Claude
- Google Gemini
- Mistral AI
We are recommending OpenAI, because it is still the state of the art AI solution on the market. OpenAI is using Microsoft Azure data centers, and it is possible to opt out of data retention and EU data centers can be requested.
Pros:
- Flexibility
- Better understanding of the context
- Rapid model development
- Multimodal (text and image input)
- Can be used for additional features like customer service chat bot, etc.
- No local server infrastructure is needed
Cons:
- Data privacy concerns
- Vendor lock-in (however OpenAI’s API is used by many other LLMs)
- Acts as a black box
Open source LLM’s
An open source Large Language Models is a generative AI solution which can be deployed and trained locally. The basic model has a thorough initial training that enables it to understand the context, while it is possible to train the model in a specific fi
Examples for open source/weight LLM’s:
- Meta Llama
- Google Gemma
We are recommending Meta’s Llama model, which is developed rapidly and it has multimodal capabilities (Llama3.2 can process images).
Pros:
- No data privacy concern
- No vendor lock-in
- Unique solution (on the long term by training the model)
- Code transparency
- Full control
Cons:
- Higher upfront costs because local server infrastructure is needed
- Accuracy depends on the size of the modell, a bigger model needs higher server performance
- Scalability
- Server utilization
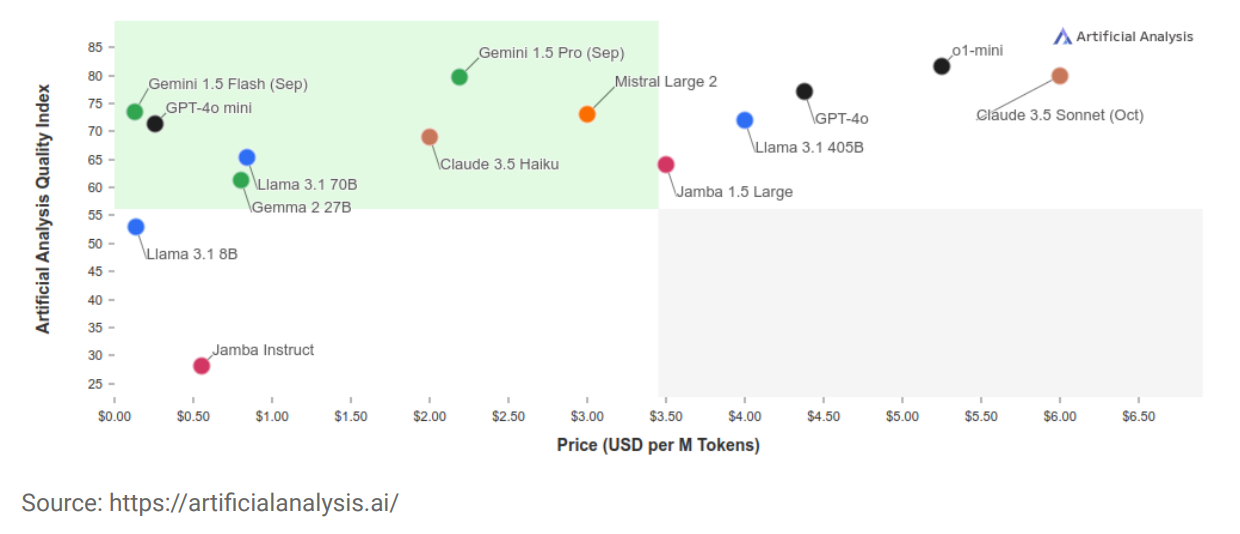
Conclusion
It is difficult to predict the performance of an AI model for a specific use case. On the one hand the models are extremely complex and non-deterministic but on the other hand the input PDF documents are heterogeneous: some have been scanned, and also formatting can be different. We have to take into account that this is an area that changes very quickly, so it is not worth committing to one supplier or solution.
Efforts should be made to integrate the language model in an easily interchangeable way, so that the benefits of new versions or more advanced models that are releas later can be more easily utilized and thus reducing the dependency on vendors.
by András Kenéz, Head of Software Development, Software Architect
Unstructured document processing strategies
In our opinion, there are 3 different approaches worth considering when looking for a solution to help us process unstructured documents:
- Cloud based document processing services
- Proprietary LLM’s
- Open source LLM’s
Cloud based document processing services
Cloud providers are offering specialized tools for extracting data from documents, for example:
- AWS (Textract)
- Azure (AI Document Intelligence)
- Google (Document AI)
These solutions are similar and have many features like OCR, table extraction, filters, etc built in, and they support many document formats out of the box. We can not run these services locally. To use these services, we must integrate using API’s, so the source documents must be submitted to the cloud.
Pros:
- Getting started is easier
- Accuracy
- Scalability
- No local server infrastructure is needed
Cons:
- Vendor lock-in
- Limited flexibility
- Data privacy concerns
Proprietary LLM’s
The well known AI providers are offering APIs to their Large Language Model. When using this approach, we must submit the prepared document to the model through its API, and the processing is taking place in the provider's infrastructure.
Examples for proprietary LLM’s:
- OpenAI GPT
- Anthropic Claude
- Google Gemini
- Mistral AI
We are recommending OpenAI, because it is still the state of the art AI solution on the market. OpenAI is using Microsoft Azure data centers, and it is possible to opt out of data retention and EU data centers can be requested.
Pros:
- Flexibility
- Better understanding of the context
- Rapid model development
- Multimodal (text and image input)
- Can be used for additional features like customer service chat bot, etc.
- No local server infrastructure is needed
Cons:
- Data privacy concerns
- Vendor lock-in (however OpenAI’s API is used by many other LLMs)
- Acts as a black box
Open source LLM’s
An open source Large Language Models is a generative AI solution which can be deployed and trained locally. The basic model has a thorough initial training that enables it to understand the context, while it is possible to train the model in a specific fi
Examples for open source/weight LLM’s:
- Meta Llama
- Google Gemma
We are recommending Meta’s Llama model, which is developed rapidly and it has multimodal capabilities (Llama3.2 can process images).
Pros:
- No data privacy concern
- No vendor lock-in
- Unique solution (on the long term by training the model)
- Code transparency
- Full control
Cons:
- Higher upfront costs because local server infrastructure is needed
- Accuracy depends on the size of the modell, a bigger model needs higher server performance
- Scalability
- Server utilization
Conclusion
It is difficult to predict the performance of an AI model for a specific use case. On the one hand the models are extremely complex and non-deterministic but on the other hand the input PDF documents are heterogeneous: some have been scanned, and also formatting can be different. We have to take into account that this is an area that changes very quickly, so it is not worth committing to one supplier or solution.
Efforts should be made to integrate the language model in an easily interchangeable way, so that the benefits of new versions or more advanced models that are releas later can be more easily utilized and thus reducing the dependency on vendors.
by András Kenéz, Head of Software Development, Software Architect
